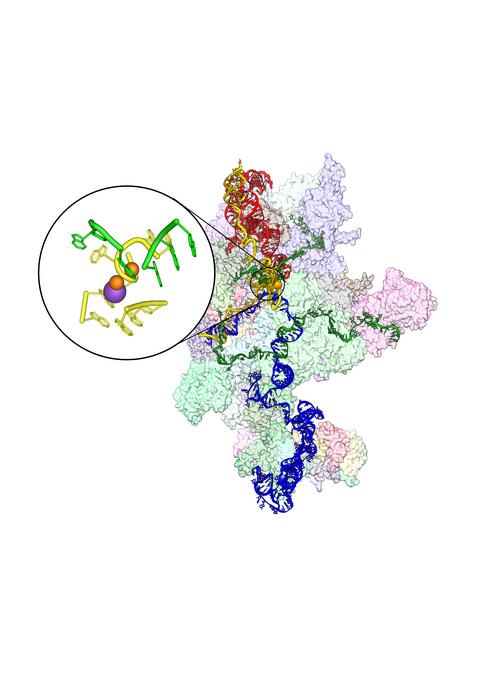
In a breakthrough that underscores the transformative power of high-performance computing, researchers are harnessing supercomputers to peer into one of biology’s most intricate and essential processes, gene splicing, bringing humanity closer to decoding the fundamental mechanisms of life itself.
A new study led by the Istituto Italiano di Tecnologia (IIT), in collaboration with Uppsala University and AstraZeneca, demonstrates how advanced computational simulations can reveal the dynamic inner workings of human cells at an unprecedented scale. At the heart of the discovery is not just biology, but the extraordinary capability of modern supercomputing.
Simulating Life at the Atomic Scale
Researchers used state-of-the-art high-performance computing (HPC) systems to construct and simulate a molecular model of about two million atoms. Achieving this scale would not be possible without supercomputers.
These simulations focused on RNA splicing, a vital step in gene expression. In this process, cells edit genetic instructions before making proteins. Splicing is experimentally elusive due to its complexity. However, it becomes tractable when modeled with computational chemistry, if enough computing power is available.
Supercomputers enabled scientists to observe the functional dynamics of this massive biological system in motion, capturing subtle interactions and transient states that traditional methods cannot resolve.
The HPC Advantage: From Data to Discovery
This work exemplifies a broader trend: supercomputers are no longer just tools for processing data; they are engines of discovery.
By solving vast numbers of equations and simulating atomic interactions in parallel, HPC systems allow researchers to:
- Reconstruct biological processes in realistic detail.
- Interpret previously ambiguous experimental data.
- Predict how molecular systems behave under different conditions.
As seen in this study, the ability to simulate millions of atoms simultaneously offers a new perspective on biological complexity, transforming static knowledge into a dynamic understanding.
Toward Precision Medicine
The implications extend far beyond academic insight. By clarifying how splicing operates—and sometimes malfunctions, scientists can begin to design molecules that precisely influence this process.
Such control could unlock new therapies for cancer and neurodegenerative diseases, where splicing errors often play a critical role.
Here, supercomputing acts as a bridge between disciplines: linking physics, chemistry, and biology to accelerate drug discovery pipelines and reduce reliance on costly trial-and-error experimentation.
A Glimpse of the Future
This achievement reflects a larger evolution in science, one where computation stands alongside theory and experiment as a foundational pillar.
From modeling proteins to simulating entire cellular systems, supercomputers are enabling researchers to ask, and answer, questions that were once unimaginable. As HPC systems continue to grow in power and efficiency, their role will only deepen, driving innovation across life sciences and beyond.
In the quest to understand life at its most fundamental level, supercomputing is proving not just useful, but indispensable.

