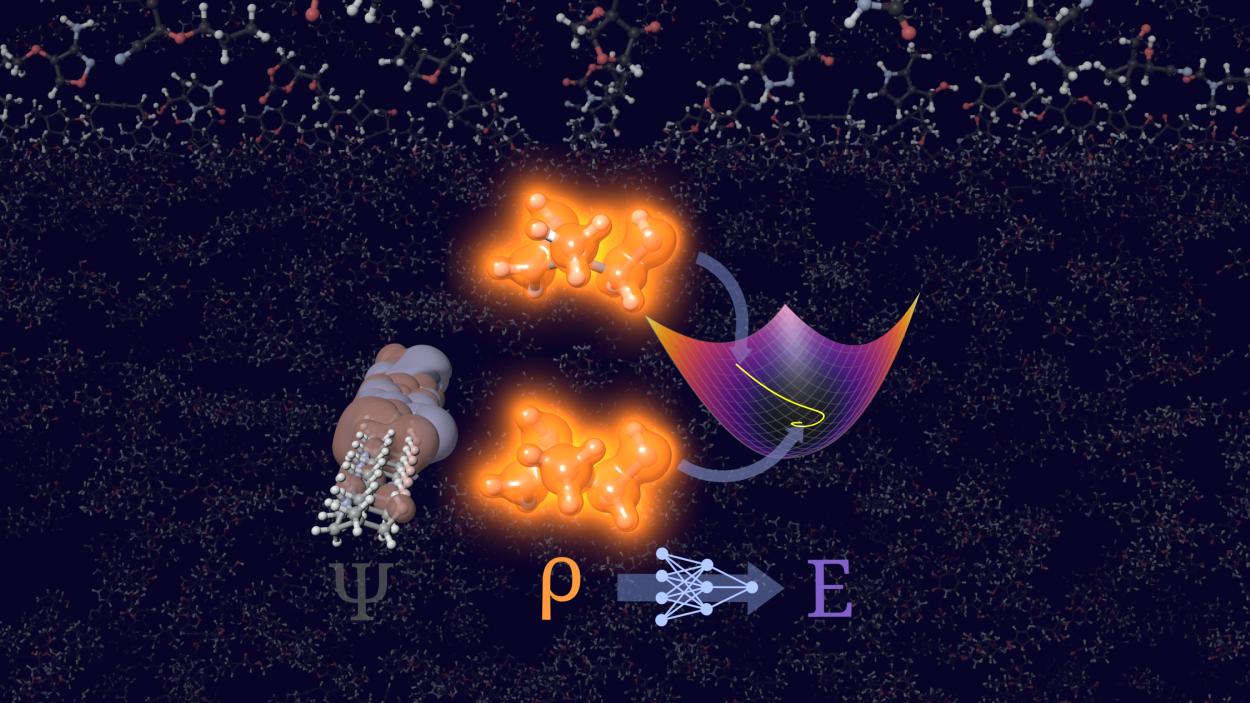
Today's press release from Heidelberg University in Germany highlights a notable advance in quantum chemistry: researchers have leveraged “scientific artificial intelligence” to address a longstanding challenge, calculating molecular energies and electron densities without relying on orbitals. This approach, called orbital-free density functional theory (OF-DFT), has often been dismissed as impractical because even small errors in electron density can lead to non-physical outcomes. The university’s new AI-driven model, STRUCTURES25, reportedly overcomes these hurdles by stabilizing the calculations and producing physically meaningful results, even for more complex molecules.
The main appeal of this orbital-free method is efficiency: by bypassing the explicit calculation of quantum mechanical wave functions (orbitals), which become computationally expensive as system size grows, chemists could significantly cut computational costs and enable simulations of much larger molecules, a persistent barrier in materials design, drug discovery, and energy research.
At its core, the new method trains a neural network to map electron density directly to energy and other quantum properties, using training data from conventional, more expensive quantum chemical calculations. The researchers emphasize that their model was trained not just on optimal solutions, but also on perturbed data around the correct answer, a strategy they argue helps the system avoid getting “lost” in unphysical results during prediction. The result? According to the team, STRUCTURES25 achieves a level of accuracy competitive with established reference methods while scaling more efficiently with molecular size.
The press materials present these findings as a major triumph for scientific artificial intelligence, implicitly suggesting that AI has matured enough to solve central problems of quantum chemistry. Yet a closer look reveals reasons for cautious interpretation, especially for SC Online’s technically informed readership.
Promise vs. Practicality
The underlying scientific goal, constructing a reliable density functional that predicts energy from electron density alone, is grounded in the Hohenberg-Kohn theorems, which mathematically guarantee that such a functional exists. But the theorems do not tell us how to find it, and decades of theoretical work have shown that constructing an exact, universally accurate functional remains elusive.
Most practical quantum chemistry remains anchored in Kohn-Sham density functional theory (KS-DFT), which introduces orbitals to approximate the true many-electron problem with usable accuracy while still facing steep computational cost. OF-DFT, in contrast, has always struggled with accuracy because the electron kinetic energy, a dominant contributor to total molecular energy, is not known exactly in terms of density alone. Supervised machine learning can fit complex mappings, but it does not change the fact that the underlying physics is approximated rather than derived from first principles.
Even the most recent advances in the field acknowledge that machine learning can narrow the gap between theory and practice, but they stop short of claiming a definitive solution. For example, a recent paper in the Journal of the American Chemical Society demonstrates that ML-enhanced orbital-free DFT can achieve chemical accuracy for a benchmark dataset when trained with high-quality reference data, a noteworthy achievement on its own, yet it depends on that reference data and its applicability outside trained molecular classes is still an open question.
The AI Hype Trap
This distinction matters: while AI-driven models like STRUCTURES25 can accelerate and scale certain calculations, they do not replace the fundamental approximations and assumptions of the underlying physics. The model’s success on organic molecules drawn from benchmark sets is a necessary proof of concept, but it is not yet evidence that AI has unlocked a universal remedy for the computational complexity of quantum chemistry. Indeed, even classical machine learning approaches applied to OF-DFT have shown promise in limited domains but struggle with generalization beyond trained chemical spaces.
For researchers in computational science and supercomputing, the real takeaway should be this: AI can be a powerful tool when combined with robust physical models and vast computational resources, but it is not a silver bullet that magically solves NP-hard problems in quantum mechanics. Supercomputers remain indispensable for generating the high-quality reference calculations needed to train and validate these models, and HPC continues to be the arena where theory, data, and computation intersect.
Where Future Challenges Remain
Key questions include:
* How well do AI-trained orbital-free models generalize to systems outside their training data?
* Can such models maintain physical consistency in extreme chemical environments, such as transition metal complexes or excited states?
* Do the computational savings of orbital-free approaches outweigh the costs of generating training data on large supercomputing installations?
* Can such models maintain physical consistency in extreme chemical environments, such as transition metal complexes or excited states?
* Do the computational savings of orbital-free approaches outweigh the costs of generating training data on large supercomputing installations?
Until such questions are rigorously addressed, claims of “solving” central problems with AI should be viewed with an appropriately critical lens, not to dismiss progress, but to contextualize it.
In summary, the Heidelberg work represents an interesting computational advance built on the interplay between machine learning and quantum chemistry. But rather than signifying a definitive breakthrough, it fits into a broader pattern: AI augments existing methods and enriches the toolkit of computational chemistry, yet still depends on supercomputing and fundamental physics to realize its potential.