Research conducted by the Computational Neuroscience Unit at the Okinawa Institute of Science and Technology Graduate University (OIST) has shown for the first time that a computer model can replicate and explain a unique property displayed by a crucial brain cell. Their findings, published today in eLife, shed light on how groups of neurons can self-organize by synchronizing when they fire fast.
The model focuses on Purkinje neurons, which are found within the cerebellum. This dense region of the hindbrain receives inputs from the body and other areas of the brain in order to fine-tune the accuracy and timing of movement, among other tasks.
“Purkinje cells are an attractive target for computational modeling as there has always been a lot of experimental data to draw from,” said Professor Erik De Schutter, who leads the Computation Neuroscience Unit. “But a few years ago, experimental research into these neurons uncovered a strange behavior that couldn’t be replicated in any existing models.”
These studies showed that the firing rate of a Purkinje neuron affected how it reacted to signals fired from other neighboring neurons. {module INSIDE STORY}
The rate at which a neuron fires electrical signals is one of the most crucial means of transmitting information to other neurons. Spikes, or action potentials, follow an “all or nothing” principle – either they occur, or they don’t – but the size of the electrical signal never changes, only the frequency. The stronger the input to a neuron, the quicker that neuron fires.
But neurons don’t fire in an independent manner. “Neurons are connected and entangled with many other neurons that are also transmitting electrical signals. These spikes can perturb neighboring neurons through synaptic connections and alter their firing pattern,” explained Prof. De Schutter.
Interestingly, when a Purkinje cell fires slowly, spikes from connected cells have little effect on the neuron’s spiking. But, when the firing rate is high, the impact of input spikes grows and makes the Purkinje cell fire earlier.
“The existing models could not replicate this behavior and therefore could not explain why this happened. Although the models were good at mimicking spikes, they lacked data about how the neurons acted in the intervals between spikes,” Prof. De Schutter said. “It was clear that a newer model including more data was needed.”
Testing a new model
Fortunately, Prof. De Schutter’s unit had just finished developing an updated model, an immense task primarily undertaken by now former postdoctoral researcher, Dr. Yunliang Zang.
Once completed, the team found that for the first time, the new model was able to replicate the unique firing-rate dependent behavior.
In the model, they saw that in the interval between spikes, the Purkinje neuron’s membrane voltage in slowly firing neurons was much lower than the rapidly firing ones.
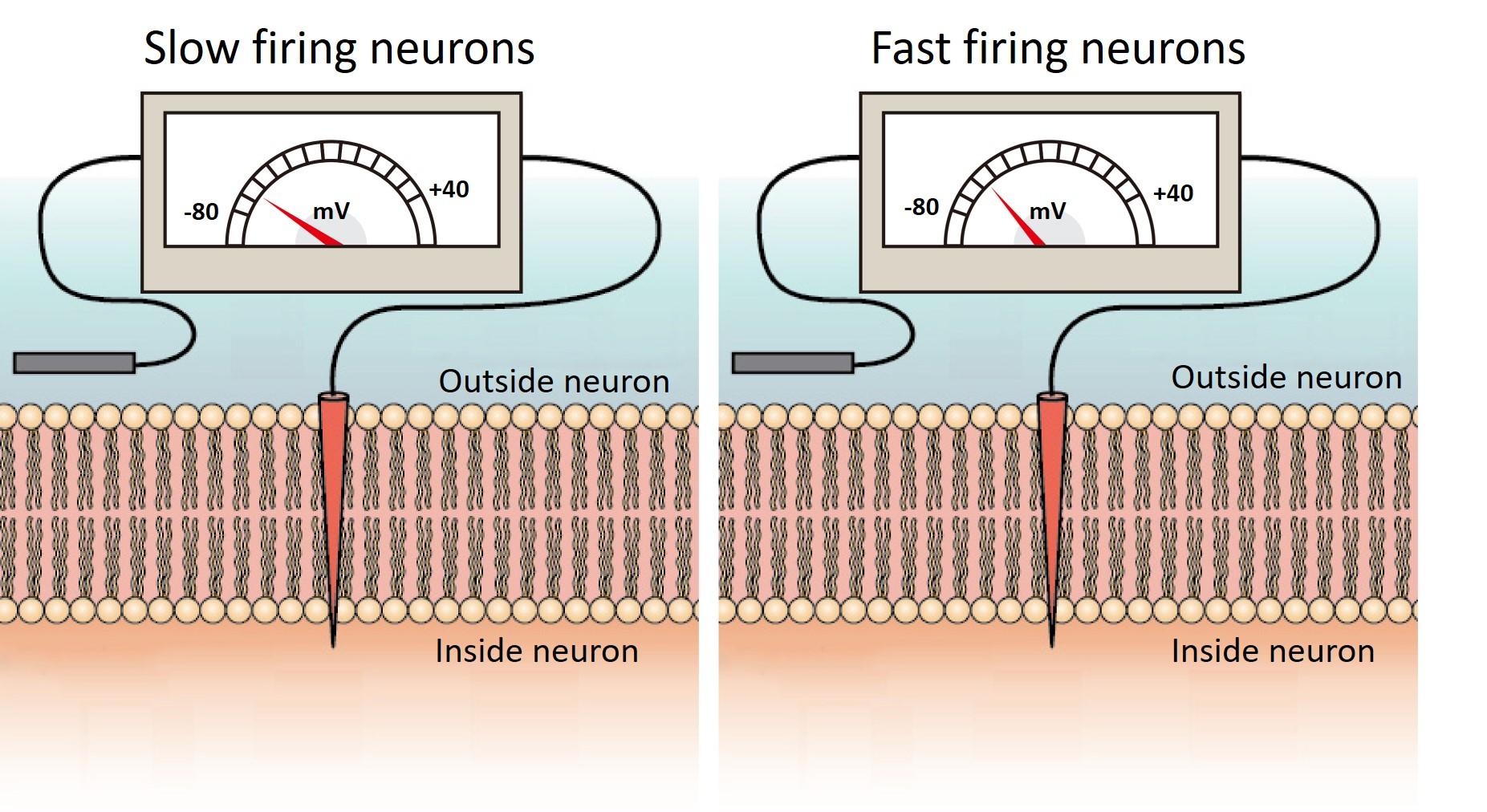
Cell membranes have a voltage across them due to the uneven distribution of charged particles, called ions, between the inside and outside of the cell. Neurons can shuttle ions across their membrane through channels and pumps, which changes the voltage of the membrane. Fast firing Purkinje neurons have a higher membrane voltage than slow firing neurons.
Credit:
Image modified from "How neurons communicate: Figure 2," by OpenStax College, Biology (CC BY 4.0).
“In order to trigger a new spike, the membrane voltage has to be high enough to reach a threshold. When the neurons fire at a high rate, their higher membrane voltage makes it easier for perturbing inputs, which slightly increase the membrane voltage, to cross this threshold and cause a new spike,” explained Prof. De Schutter.
The researchers found that these differences in the membrane voltage between fast and slow firing neurons were because of the specific types of potassium ion channels in Purkinje neurons.
“The previous models were developed with only the generic types of potassium channels that we knew about. But the new model is much more detailed and complex, including data about many Purkinje cell-specific types of potassium channels. So that’s why this unique behavior could finally be replicated and understood,” said Prof. De Schutter.
The key to synchronization
The researchers then decided to use their model to explore the effects of this behavior on a larger-scale, across a network of Purkinje neurons. They found that at high firing rates, the neurons started to loosely synchronize and fire together at the same time. Then when the firing rate slowed down, this coordination was quickly lost.
Using a simpler, mathematical model, Dr. Sungho Hong, a group leader in the unit, then confirmed this link was due to the difference in how fast and slow firing Purkinje neurons responded to spikes from connected neurons.
“This makes intuitive sense,” said Prof. De Schutter. He explained that for neurons to be able to sync up, they need to be able to adapt their firing rate in response to inputs to the cerebellum. “So this syncing with other spikes only occurs when Purkinje neurons are firing rapidly,” he added.
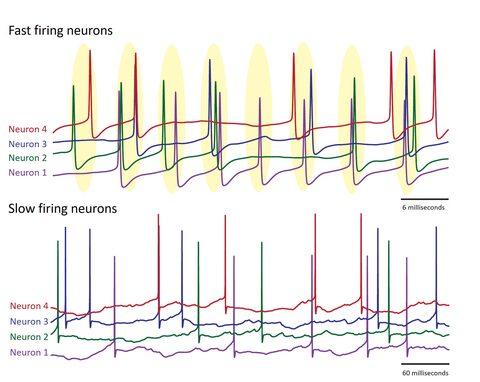
When a group of Purkinje neurons fire rapidly, loose synchronization occurs. This can be seen by the spikes occurring in groups at regular intervals (highlighted in yellow). When Purkinje neurons fire slowly, this synchronization does not occur.
The role of synchrony is still controversial in neuroscience, with its exact function remaining poorly understood. But many researchers believe that synchronization of neural activity plays a role in cognitive processes, allowing communication between distant regions of the brain. For Purkinje neurons, they allow strong and timely signals to be sent out, which experimental studies have suggested could be important for initiating movement.
“This is the first time that research has explored whether the rate at which neurons fire affects their ability to synchronize and explains how these assemblies of synchronized neurons quickly appear and disappear,” said Prof. De Schutter. “We may find that other circuits in the brain also rely on this rate-dependent mechanism.”
The team now plans to continue using the model to probe deeper into how these brain cells function, both individually and as a network. And, as technology develops and supercomputing power strengthens, Prof. De Schutter has an ultimate life ambition.
“My goal is to build the most complex and realistic model of a neuron possible,” said Prof. De Schutter. “OIST has the resources and supercomputing power to do that, to carry out really fun science that pushes the boundary of what’s possible. Only by delving into deeper and deeper detail in neurons, can we really start to better understand what’s going on.”


 with an ESO artist impression (left) CREDIT ESO/L. Calçada, Exeter/Kraus et al.") {module INSIDE STORY}
{module INSIDE STORY}